Aktualisiert: 2024-02-21
Diese Varianten oder Versionen arbeiten mit einer persistenten Speicherung der Daten im nichtflüchtigen Speicher eines Shelly der zweiten Generation, hier einem Shelly Plus 1 mit AddOn und digitalem Temperatursensor. Diese Datenspeicherung hat gegenüber derjenigen im flüchtigen Speicher (RAM) entscheidende Vorteile.
Den initiierenden Hinweis dazu bekam ich aus einem Forum von einem mit mir konstruktiv kommunizierenden Mitglied aus Ostfriesland. Weitere nützliche Informationen steuerte ein ebenfalls konstruktiv kommunizierendes Mitglied aus Baden-Württemberg bei. Ich danke beiden.
Inhalt
- Vorteile der persistenten Speicherung
- Methoden für den Zugriff auf die Daten
- Eigenschaften und Verhaltensweisen
- Datenübertragung
- Empfänger
- Experimente und Testmöglichkeiten
- Optionale Weiterentwicklung
- "Tagebuch"
Vorteile der persistenten Speicherung
- Bis zu einem Stromausfall gespeicherte Daten bleiben erhalten. Nach dem Stromausfall wird die Speicherung (mit Einschränkung, s.u.) fortgesetzt.
- Man kann den Shelly von der Versorgung trennen und zwecks Datenübertragung mitnehmen.
- Man kann sich die Daten per Web UI direkt im Browser ansehen und sogar per C&P kopieren, wenn eine vorgesehene Übertragung fehlschlagen sollte.
Einschränkung
Die persistente Datenspeicherung kann bei Stromausfall den Verlust der von der Firmware verwalteten Zeitinformation Datum und Uhrzeit bzw. Unix Timestamp nicht beseitigen. Hierfür braucht der Shelly kurzzeitig eine Verbindung zu einem Zeitserver, also eine Verbindung zu einem WLAN (und ggf. Internet), wozu auch eine kurzzeitige Verwendung eines Smartphone als Hotspot geeignet ist - ca. 1 Minute sollte genügen. Grund: Der hier eingesetzte Shelly verfügt über keine Echtzeituhr, welche bei Stromausfall weiterläuft.
Methoden für den Zugriff auf die Daten
Die hier verwendete Speicherung nutzt das Dateisystem der Shelly Firmware, welches vermutlich bisher ausschließlich zum speichern der Skripte vorgesehen ist. Diese Dateien können per RPC-Aufrufe (Remote Procedure Call) mit ID-Nummern angelegt, gelöscht, beschrieben und gelesen werden. Für die hier erforderlichen Zugriffe stehen folgende RPC-Methoden zur Verfügung.
- "Script.List" liefert die Liste aller Dateien, welche normalerweise Skripte sind. Die Liste ist ein Objekt, welches im wesentlichen ein Datenfeld beinhaltet, dessen Elemente aus den Komponenten id, name, enable, und running bestehen. Hier werden ausschließlich id und name verwendet, um zum vorgegebenen Dateinamen "data" die ID der Daten-Datei zu ermitteln. Diese ID ist für die folgenden RPC-Methoden erforderlich, der Dateiname spielt dabei keine Rolle mehr.
- Mit "Script.Create" kann eine Datei angelegt werden, diese Methode liefert deren ID.
- Per "Script.PutCode" können beliebige Texte in eine Datei geschrieben werden. Die zu speichernden Daten werden somit als Texte gespeichert. Sie können den bisherigen Inhalt ersetzen oder daran angefügt werden.
- "Script.GetCode" dient dem Lesen aus einer Datei. Als Parameter können der Beginn des Lesens (offset = Abstand vom Dateianfang in Bytes) und die Länge (len = Anzahl an zu lesenden Bytes) angegeben werden. Diese Parameter nutze ich zur sequentiellen Übertragung der gespeicherten Daten als Pakete in MQTT Nachrichten. Die Methode liefert neben den gelesenen Daten (Text) die restliche Anzahl an Bytes bis zum Dateiende.
- Mit "Script.Delete" kann eine Datei aus dem nichtflüchtigen Speicher "entfernt" werden, wobei vermutlich nur ein Eintrag in einer Firmware internen Liste entfernt wird. Diese Methode nutze ich derzeit nicht.
Eigenschaften und Verhaltensweisen
Das bisher vorliegende Skript implementiert folgende Eigenschaften und Verhaltensweisen.
- Es ermittelt die ID zur Datei mit dem Namen "data". Gibt es keine solche Datei, wird sie angelegt, zunächst ohne Inhalt.
- Jede Zeile in "data" besteht aus einem Datensatz, dessen Struktur innerhalb einer Skriptfunktion für eigene Zwecke festgelegt werden kann. Derzeit besteht ein Datensatz aus dem Unix Timestamp, einem Komma, dem gemessenen Temperaturwert und einem Zeilenvorschub. Die Textlänge des Temperaturwertes ist auf 4 festgelegt, wozu unter Umständen Leerzeichen vorne angefügt werden. Somit ergibt sich für jeden Datensatz eine feste Länge von insgesamt 16 Bytes. Diese feste Länge dient dem Berechnen von offset und len (Parameter der Methode "Script.GetCode") zum lesen einer festen Anzahl an Datensätzen. Letztere werden sequentiell in MQTT Nachrichten gesendet.
- Wenn die Verbindung zum eingetragenen MQTT Broker besteht, werden sechs Statusinformationen gesendet. Diese Informationen gestatten dem Anwender, den Skriptablauf unter Verwendung eines Dashboards zu steuern und zu überwachen.
- Anstoßen einer Datenübertragung und anzeigen dieser
- Fortschritt der Datenübertragung in %
- Aktueller Aufzeichnungsmodus (Speicherung im Shelly):
- neu gestartet - die Speicherung in "data" beginnt von vorne
- angehalten - eine Speicherung findet aktuell nicht statt, bspw. während einer Datenübertragung
- fortgesetzt - die Messwerte werden an die bisher gespeicherten angehängt
- Aktueller Füllstand des lokalen Speichers, also Länge der Datei "data" / Limit
Das Limit wird im Skript festgelegt, aktuell 20480 Bytes. - Datum und Uhrzeit der letzten Datenübertragung
- Datum und Uhrzeit der letzten Statusnachricht
Im Vergleich mit der aktuellen Zeit kann der Anwender erkennen, ob der Shelly gegenwärtig eine Verbindung zum eingetragenen MQTT Broker hat. - Der obige, letzte Punkt ist obsolet, kann aber trotzdem noch genutzt werden. Ich werte inzwischen den in MQTT möglichen "Last Will and Testament" (LWT) bzw. die vom Shelly automatisch nach Verbindungsaufbau gesendete retained Nachricht aus. Beide haben dasselbe Topic und nur unterschiedliche Payloads. Die LWT Payload ist "false", die Online Payload ist "true". Damit kann jederzeit von einem MQTT Client festgestellt werden, ob der Shelly online ist oder nicht.
- Folgende Parameter können per KVS (Key Value Storage) festgelegt werden. Sie besitzen default Werte, welche im Skript eingetragen sind. Die im KVS festgelegten Parameter überschreiben die default Werte.
- "transmit_restart", Wert true oder false, legt fest, ob nach einer abgeschlossenen Datenübertragung eine neue Aufzeichnung begonnen wird (true). Bei false wird dann die Speicherung angehalten.
- "transmit_size", Wert eine Anzahl, legt die Anzahl an Datensätzen fest, die in einer MQTT Nachricht übertragen werden. Je größer diese Anzahl ist, desto weniger Nachrichten werden für die gesamte Übertragung benötigt, desto mehr RAM Speicher zur Pufferung wird allerdings erforderlich.
- "transmit_wait", Wert eine Dauer in ms, legt die Wartezeit zwischen dem Versenden zweier MQTT Nachrichten innerhalb einer kompletten Datenübertragung fest. Je größer dieser Wert ist, desto wahrscheinlicher treffen die Daten in der passenden Reihenfolge beim Empfänger (MQTT Subscriber) ein. Dann dauert die gesamte Übertragung selbstverständlich länger.
- Das MQTT Pretopic kann im KVS per Key "topic_pre" eingetragen werden. Darin muss statt eines Slash (/) ein Punkt verwendet werden, weil die Firmware den Slash codiert. Im Skript wird beim lesen jeder Punkt durch einen Slash ersetzt. Alle kompletten Topics, bestehend aus dem Pretopic und nachfolgenden Spezialisierungen werden fest im Skript zusammengestellt und können nur darin geändert werden.
- Das Speichern der (gemittelten) Messwerte und Zeitstempel werden per Schedule Job (Zeitplan) getriggert. Dieser Schedule Job muss im Shelly angelegt werden. Hierfür steht meine Website tools.eichelsdoerfer.net zur Verfügung. Die dort befindliche Webseite https://tools.eichelsdoerfer.net/schedjob.html ist wenig für DAUs geeignet 😋, bietet aber flexible Möglichkeiten zum anlegen, löschen und verändern eines solchen Schedule Jobs. Unter Funktionsaufruf ist für dieses Projekt immer "store()" (ohne Anführungszeichen) einzutragen. Als timespec Wert ist normalerweise folgender Eintrag geeignet: "0 */<alle wieviel Minuten> * * * *" - Wichtig: jeweils ein Leerzeichen dazwischen. Soll bspw. rund um die Uhr alle 12 Minuten auf dem Shelly ein Datensatz (Zeitstempel und gemittelter Messwert) gespeichert werden, gelingt dies mit "0 */12 * * * *". Wenn täglich alle 5 Minuten zwischen 7:00 Uhr und 23:00 Uhr gespeichert werden soll, lautet der timespec Wert "0 */5 7-23 * * *". Der timespec Wert kann ab Firmware 1.2.0 relativ leicht in der Web UI geändert werden. Siehe hierzu auch den Beitrag "Mächtige Schedule Jobs" auf dieser Website.
- Um die Datenübertragung per MQTT zu ermöglichen, muss der bevorzugte MQTT Broker in der Shelly Konfiguration eingetragen werden. Dies kann ein öffentlicher Broker, wie "test.mosquitto.org:1883" oder ein selbst installierter sein, der zu Hause arbeitet. Bei Letzterem ist der Shelly nach Hause zu transportieren. Der Anwender kann hierfür zwei Messstationen verwenden, die er zwecks Datenübertragung austauscht.
Datenübertragung
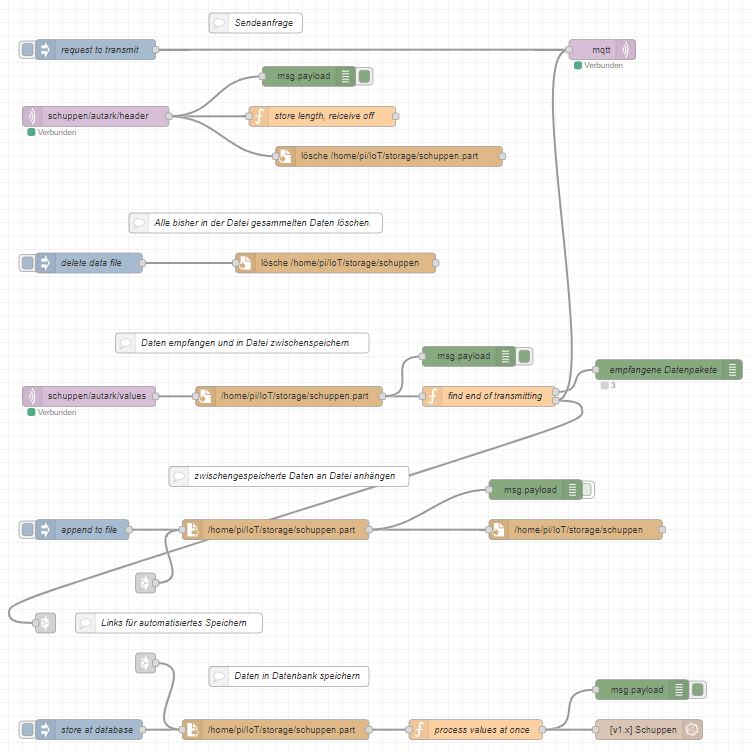
Derzeit werden die einzelnen MQTT Nachrichten (Datenpakete) ohne Zusatzinformation versendet, also als schlichte Texte. Diese Texte sind Kopien aus der Datei "data". Vor diesen Datenpaketen wird eine Nachricht als Header gesendet, in welchem u.a. die folgende Anzahl an Datenpaketen enthalten ist. Es wird somit eine Länge gesendet und keine Abschlussnachricht. Der Empfänger muss somit an Hand der Länge bzw. Anzahl ermitteln, wann die komplette Datenübertragung beendet ist. Hierfür habe ich einen geeigneten Node-RED Flow erstellt. Dieser Flow sendet eine MQTT Nachricht, sobald er alle Datenpakete empfangen hat. Wenn das Skript diese Nachricht erhält, entscheidet es, an Hand des Wertes der Konfigurationsvariablen "transmit_restart", ob es mit einer neuen Aufzeichnung beginnt oder die Aufzeichnung pausieren lässt. Im zweiten Fall ist es dem Anwender überlassen, mit einer MQTT Dash Kachel dem Skript mitzuteilen, dass es die Aufzeichnung neu starten oder fortführen soll.
Diese Übertragungsstruktur ist sehr schlicht und kann bei Bedarf von mir mit redundanten und/oder ordnenden Informationen angereichert werden. Hierzu denke ich an einen Index, welcher jedem Datenpaket hinzugefügt wird. Damit ließe sich im Empfänger die eintreffenden Pakete in die richtige Reihenfolge ordnen.
Empfänger
Als Empfänger steht der erwähnte Node-RED Flow zur Verfügung. Dieser speichert die empfangenen Datenpakete schlicht in der eintreffenden Reihenfolge in einer Datei zwischen. Der Flow zählt die eintreffenden Datenpakete und stellt fest, wenn alle Pakete empfangen wurden. Erst dann bestätigt er den kompletten Empfang aller Pakete per MQTT Nachricht. Die zwischengespeicherten Datensätze können per Anklicken eines inject node einer Sammeldatei für alle Datensätze angehängt werden. Zusätzlich oder alternativ können durch Anklicken eines anderen inject node diese Datensätze in einer Influx Datenbank abgelegt werden - um diese bspw. per grafischer Darstellungen dem Anwender anschaulich präsentieren zu können. Für Letzteres kann ich Grafana sehr empfehlen.
Zwecks Automatisierungen beider abschließender Speichervorgänge (Datei und/oder Datenbank) stehen drei link nodes zur Verfügung, ein link out node und zwei link in nodes. Zur automatischen Endspeicherung nach der kompletten Datenübertragung ist nur die passende Verbindung zwischen dem link out node und einem oder beiden link in nodes herzustellen. Der Flow und diese Verbindungen sind im Flow beschrieben.
Mit jeder beginnenden Datenübertragung, konkret: eintreffen einer Header Nachricht, wird die zwischenspeichernde Datei automatisch gelöscht und zur Zwischenspeicherung neu angelegt. Sollen die empfangenen Daten dauerhaft gespeichert werden, ist zumindest einer der beiden o.a. Schritte durchzuführen bzw. zu automatisieren.
Experimente und Testmöglichkeiten
Sowohl die vorgesehene Konfiguration im KVS des Shelly als auch der etwas offene Node-RED Flow sind dazu geeignet, die Funktionsweise und -sicherheit der Implementation zu betrachten und zu prüfen. Mit wenigen geeigneten Eingriffen ist das gewünschte Verhalten der Anwendung herstellbar. Ich empfehle, zunächst mit allen Optionen zu experimentieren, um diese Anwendung hinreichend kennenzulernen.
Zur Nutzung empfehle ich zusätzlich die Installation der Android App "MQTT Dash" auf einem Smartphone oder Tablet. Damit lässt sich die Datenübertragung sehr gut steuern und überwachen. Die von mir eingerichteten sechs Kacheln können leicht und zügig auf ein anderes Android Smartphone kopiert werden.
Hier ein Screenshot der Kacheln, mit denen die Übertragung gestartet und überwacht werden kann. Zusätzlich kann die Aufzeichnung der Daten angehalten, fortgesetzt oder neu gestartet werden. Auch der Füllstand des vorgesehenen Speichers wird angezeigt. Diese Daten sind nur dann aktuell, wenn der Shelly eine Verbindung zum eingetragenen MQTT Broker hat. Ein zusätzlicher Schedule Job kann dies bspw. jede Minute versuchen.

Selbstverständlich kann auch eine andere MQTT App genutzt und passend eingerichtet werden. Auch ein per Node-RED erstelltes Dashboard oder ein anderes übergeordnetes System wie openHAB ist dazu geeignet. Mit anderen Systemen wie ioBroker, homematic, ... habe ich keine hinreichenden Erfahrungen. Vermutlich sind auch diese hierfür verwendbar. Wenn die Übertragung am Messort über einen öffentlichen MQTT Broker stattfinden soll, wird eine App benötigt, die keine Verbindung zum übergeordneten System benötigt - es sei denn, der Shelly kann VPN nutzen. Letzteres gelang mir bisher nicht.
Optionale Weiterentwicklung
MQTT LWT Nachricht
Es sollte auch möglich sein, das MQTT LWT (Last Will and Testament) eines Shelly zu nutzen. Der Shelly sendet immer bei erfolgreicher Aufnahme der Verbindung zum MQTT Broker eine LWT Nachricht. Diese ist unter dem Topic "<ShellyTyp-MACAdresse>/online" bzw. "<Prefix>/online" zwecks abonnieren verfügbar. Bei Verlust der Verbindung sendet der Broker jedem verfügbaren Subscriber eine Nachricht mit der Payload "false". Mit hergestellter Verbindung sendet der Broker die Payload "true". Dies geschieht nur bei einer Verbindungsänderung - erhalten oder verloren. Damit sollte es bei einer verlässlichen WLAN-Verbindung möglich sein, sofort nach Verbindungsaufnahme den Online Status im MQTT Frontend (bspw. MQTT Dash) zu erkennen.
Dies ist inzwischen als Kleinigkeit implementiert. Dazu ist nur ein weiterer MQTT Subscriber (bspw. eine MQTT Dash Kachel) erforderlich, welcher das Topic <Prefix>/online abonniert. Immer wenn sich dieser Subscriber am Broker anmeldet, erhält er die Nachricht (Payload) "false" oder "true".
Datenspeicherung und -zusammenstellung
Es können mehr Informationen bei zugleich höherer Datendichte gespeichert werden. Ich setze hier voraus, dass das Skript ohne Fehler durchläuft, solange sich kein Stromausfall ereignet. Hierfür habe ich folgendes Konzept entworfen.
Die Informationen werden auf zwei Dateien verteilt, "data" und "time". Beiden Dateien ist gemeinsam, dass jede Zeile genau einen Datensatz enthält und eine konstante Länge besitzt. Nur so können auf einfache, schnelle und sichere Weise die Anzahl an Zeilen (=Datensätzen) und zu einer Zeilennummer der offset Parameter zum Lesen ermittelt werden. Eine Zeilennummer dient so quasi zur Adressierung eines Datensatzes. Die beiden Dateien dienen folgenden Zwecken.
- "data" zur ausschließlichen Speicherung der Messwerte, hier Temperaturwerte - ohne Zeitstempel.
Dies ergibt eine deutlich höhere Datendichte, weil der zehnstellige Zeitstempel in jedem Datensatz entfällt. Bei Bedarf kann deshalb die Abtastrate oder die Aufzeichnungsdauer ca. verdoppelt werden, ohne die erforderliche Speicherkapazität zu vergrößern. - "time" zur Speicherung von Datensätzen bestehend aus einem Zeitstempel und einer Zeilennummer, auch als Index interpretierbar. Die Zeilennummer dient als Referenz zu der Zeile in "data", zu welcher der Zeitstempel gehört. "time" ist i.d.R. sehr klein, sie beinhaltet im Idealfall, kein Stromausfall während der Aufzeichnung, nur eine Zeile. Mit dem ersten gespeicherten Datensatz in "data" zu Beginn einer Aufzeichnung wird der erste, und vorläufig einzige Zeitstempel und die Zeilennummer 1 in "time" gespeichert. Dieser Zeitstempel ist dem ersten Messwert in "data" (per Zeilennummer) zugeordnet. Mit jedem Skriptstart während einer Aufzeichnung, also nach jedem Reboot, wird "time" ein solcher Datensatz aus Zeitstempel und Zeilennummer hinzugefügt. Aus der Anzahl an Zeilen in "time" ergibt sich somit die Anzahl an Reboots während der Aufzeichnung, nämlich Reboots = "time" Zeilenanzahl - 1. In den allermeisten Fällen kann ein Reboot auf einen Stromausfall schließen lassen, was ich hiermit tue.
Mit diesem Speicherungskonzept können zumindest teilweise die Zeitstempel rekonstruiert werden. Dazu wird bereits der zeitliche Abstand zwischen zwei Speicherungen in "data" per lesen und analysieren des Schedule Jobs ermittelt und in einer Variablen dt abgelegt. Aus einem Zeitstempel ts in "time" und der Zeilennummer n lassen sich auch die nachfolgenden Zeitstempel zu den Datensätzen in "data" generieren. Hierzu sind folgende Fälle zu unterscheiden und per Skript ermittelbar.
- Es gibt genau einen Datensatz in "time". Dann ereignete sich kein Reboot, also kein Stromausfall. Zur Zeile n in "data" gehört der Zeitstempel ts + (n-1) * dt.
- Es gibt genau zwei Datensätze in "time" mit dem ersten Datensatz ts1, n1 sowie dem zweiten Datensatz ts2, n2. Dann ereignete sich genau ein Reboot, also ein Stromausfall (oder eine Störung). Da der Shelly an der Messstelle keinen Zugriff auf einen Zeitserver besitzt, ist der zweite Zeitstempel ungültig, da er nur die Zeit seit dem Reboot in Sekunden beinhaltet. Sobald der Anwender dem Shelly den Internetzugang bereitstellt, bspw. per Smartphone Hotspot, erhält der Shelly sowohl eine Verbindung zum MQTT Broker als auch eine zu einem Zeitserver. Dann besitzt der Shelly die synchronisierte Zeit. Das Skript kann eine MQTT Nachricht mit Informationen zum Stromausfall senden. Wenn der Anwender nun vor der Datenübertragung die Speicherung des nächsten Datensatzes abwartet, kann das Skript auch die richtigen Zeitstempel nach dem Stromausfall-Reboot berechnen - und zusätzlich von wann bis wann der Strom ausfiel. Der Leser mag hier selbst darüber nachdenken, wie dies gelingen kann, wenn er möchte. 😉
Einschränkung: Die Messwerte wurden nach dem Reboot mit einem zunächst unbekannten Zeitverschiebungsfehler gespeichert, weil der Scheduler temporär nicht über hinreichende Zeitinformationen verfügte. Ob und wie dieser Zeitverschiebungsfehler beschränkt oder gar ermittelt werden kann, überlasse ich dem geneigten Leser. 😁 - Es gibt mehr als zwei Datensätze in "time". Dann können prinzipiell nur noch die Anzahl an Reboots sowie die richtigen Zeitstempel vor dem ersten Reboot und nach dem letzten Reboot ermittelt werden.
Hinweis: Dazu wird jeweils ein richtiger, im Sinne von "die Uhrzeit repräsentierender" Zeitstempel als Referenz benötigt.
Dieses Speicherungskonzept besitzt gegenüber dem bisherigen, einfachen Speicherungsverfahren fast ausschließlich Vorteile, was dessen Implementation wünschenswert erscheinen lässt. Es gibt nur einen Nachteil gegenüber dem bisherigen Verfahren, Zeit und Messwert(e) in jede Zeile von "data" zu schreiben: Wenn der Anwender in der Web UI die Datei "data" im neuen Format öffnet, alle Daten markiert, in die Zwischenablage kopiert und in einer anderen Anwendung einfügt (kurz Copy & Paste), dann fehlen die Zeitinformationen, weil diese erst mit der Übertragung berechnet werden.
"Tagebuch"
2024-03-31
MQTT Dash erhielt eine weitere Kachel, über welche unmittelbar nach Herstellung zum MQTT Broker der Online Status des Shelly erkannt wird. Somit muss der Anwender nicht mehr auf eine aktuelle Zeitnachricht warten.
2024-02-14
Ich habe das Datensatzformat in "data" geändert. Vormals besaß eine Zeile die Struktur timestamp, Leerzeichen, Messwert (ggf. mit Nullen aufgefüllt). Nun besteht eine Zeile aus timestamp, Komma, Messwert (ggf. mit führenden Leerzeichen aufgefüllt). Dies erlaubt eine einfachere Konvertierung des Messwertes in eine Zahl per JSON.parse() in Node-RED. Das Auffüllen mit Leerzeichen im Skript ist einfacher. Der Import der Daten in eine Anwendung per Copy & Paste gelingt zielführender.
2024-02-11
Mit der Festlegung und Berücksichtigung des Limit für die Datendatei arbeitet das Skript bisher ohne Probleme, auch bei erreichen dieses Limit.
2024-02-08
Das System arbeitet nicht mehr, wie es soll. Vermutlich wurde die Datendatei zu groß. In der aktuellen Fassung habe ich dafür ein Limit von 20480 Bytes festgelegt. Von unserem Forumsmitglied aus Baden-Württemberg erfuhr ich, dass ein Skript bis zu max. knapp 40k Bytes aufnehmen könne. Ob dies für Nicht-JavaScript Code auch gilt, ist mir nicht bekannt.
2024-02-06
Das Skript arbeitet seit über 18 Stunden fehlerfrei und speichert alle zwei Minuten einen Datensatz. Dies sind bisher 552 Datensätze, insgesamt 552 * 16 Bytes = 8832 Bytes. Bei einer anwendungsorientierten Speicherung alle 10 Minuten ergibt dieser Speicherungsumfang eine Aufzeichnungsdauer von 92 Stunden = 3 Tage + 20 Stunden.
2024-03-31